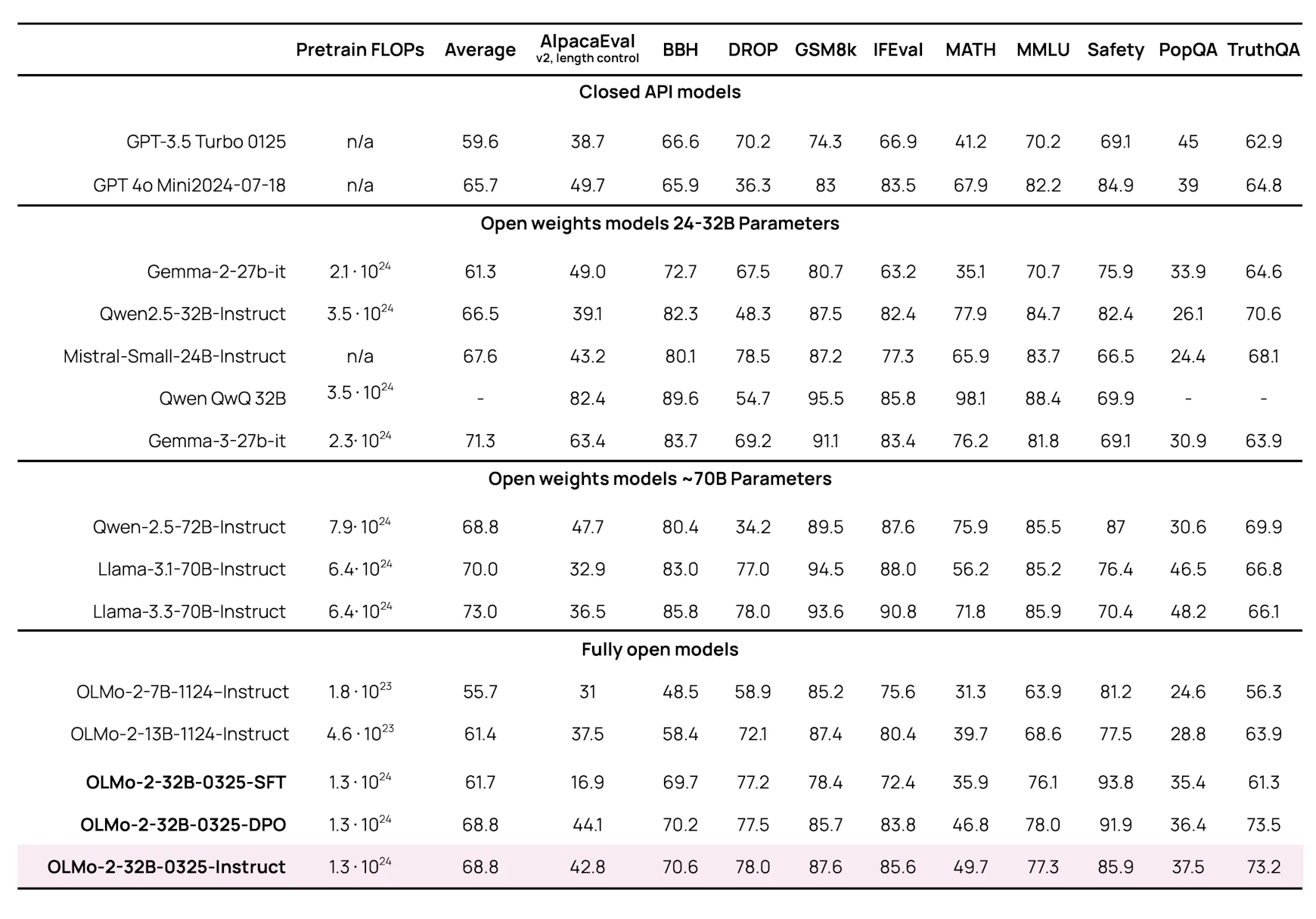
I don’t trust AllenAI for reason of deceptive marketing by using the term “Open Source”. Yes, few models are there, but the large number of their models are based on proprietary Llama. That is quite of a contradiction to their marketing of being Open Source.
Regarding that model, look better the picture:
as it is deceptive!
They claim: State-of-the-art results: OLMo 2 32B matches or outperforms GPT3.5 Turbo, GPT4-o mini, Qwen 2.5 32 B, Mistral 24B, and approaches Qwen 2.5 72B, Llama 3.1 and 3.3 70B.
OLMo-2-0325-32B vs. Mistral-Small-24B:
Average Score: OLMo-2-0325-32B (72.9) is slightly lower than Mistral-Small-24B (75.2).
Individual Metrics:
ARC/C: OLMo-2-0325-32B (90.4) is higher than Mistral-Small-24B (93.3).
HSwag: OLMo-2-0325-32B (89.7) is lower than Mistral-Small-24B (91.3).
WinoG: OLMo-2-0325-32B (78.7) is lower than Mistral-Small-24B (77.8).
MMLU: OLMo-2-0325-32B (74.9) is lower than Mistral-Small-24B (80.7).
DROP: OLMo-2-0325-32B (74.3) is lower than Mistral-Small-24B (74.4).
NQ: OLMo-2-0325-32B (50.2) is lower than Mistral-Small-24B (42.3).
AGIEval: OLMo-2-0325-32B (61.0) is lower than Mistral-Small-24B (69.1).
GSM8k: OLMo-2-0325-32B (78.8) is lower than Mistral-Small-24B (79.7).
MMLUPro: OLMo-2-0325-32B (43.3) is lower than Mistral-Small-24B (54.2).
TriviaQA: OLMo-2-0325-32B (88.0) is lower than Mistral-Small-24B (88.8).
Overall, Mistral-Small-24B performs better in most metrics compared to OLMo-2-0325-32B.
OLMo-2-0325-32B vs. Qwen-2.5-32B:
Average Score: OLMo-2-0325-32B (72.9) is lower than Qwen-2.5-32B (74.9).
Individual Metrics:
ARC/C: OLMo-2-0325-32B (90.4) is lower than Qwen-2.5-32B (95.6).
HSwag: OLMo-2-0325-32B (89.7) is lower than Qwen-2.5-32B (96).
WinoG: OLMo-2-0325-32B (78.7) is lower than Qwen-2.5-32B (84).
MMLU: OLMo-2-0325-32B (74.9) is lower than Qwen-2.5-32B (83.1).
DROP: OLMo-2-0325-32B (74.3) is higher than Qwen-2.5-32B (53.1).
NQ: OLMo-2-0325-32B (50.2) is higher than Qwen-2.5-32B (37).
AGIEval: OLMo-2-0325-32B (61.0) is lower than Qwen-2.5-32B (78).
GSM8k: OLMo-2-0325-32B (78.8) is lower than Qwen-2.5-32B (83.3).
MMLUPro: OLMo-2-0325-32B (43.3) is lower than Qwen-2.5-32B (59).
TriviaQA: OLMo-2-0325-32B (88.0) is lower than Qwen-2.5-32B (79.9).
Qwen-2.5-32B generally outperforms OLMo-2-0325-32B across most metrics.
While OLMo-2-0325-32B shows competitive performance in some metrics, it does not consistently match or outperform Mistral-Small-24B, Qwen-2.5-32B, or Llama-3.1-70B. The claim that it matches or outperforms these models is not fully supported by the data provided. OLMo-2-0325-32B performs well but is generally outperformed by the other models mentioned.
They made letters bold on that graphics:
Which is common on LLM benchmarking graphics to point out which model is better.
However, they made it bold for their model, like it is better than others, trying to make me as visitor stupid. Like I am not going to see what is the problem.
I have got a feeling they are doing it for marketing purposes more than for the actual improvements.